Often times, when curating reports for APTNotes, I come across reports which publish IoCs as images, and not text. For one-off instances, the solution to extracting text from such images is simple: type it out.
For bulk processing, using Tesseract to extract data will make this a little easier. Out of the box, Tesseract results will be not very encouraging.
Here is an example I used:
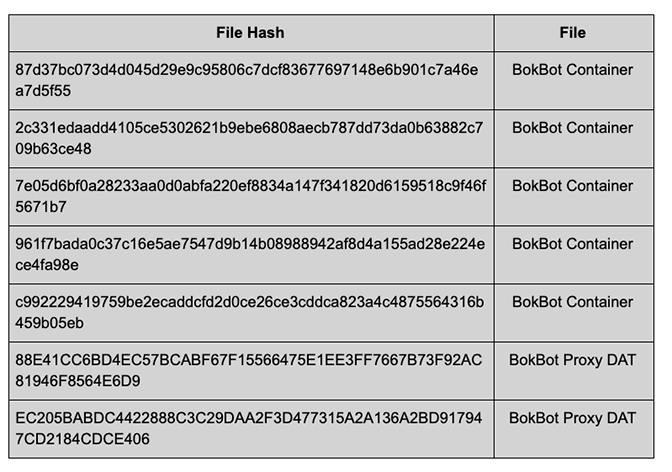
This image was an interesting testcase because of columns and the fact that the hashes are broken into two lines. Extracting raw text from this results in:
Flle Hash Filo
37d37th73flAflO45d2929c9530627flcl83677697148e6b901 673469 BokBot Container
a7d5155
2c331edaadu41050e5302621b9ehe6soaaecb’lsmd’ladaowasaziz’l Bokfiat Container
usbfisma
7e05d6Moaza233aaod0ahiazzoeiaaada147i3418200615951Bc9f46i Bokfiat Conminev
5671 D7
96117badaflc$7c1695887547d9b14h08958942alfld4a155302892249 Bokfiat Container
0346:1981:
c992229419759heZecaddcid2dnoe26m3wdm523a4m875564316b Bnkaat Container
459h059b
BBEA1CCGED4ECS7BCABF67F15565475E1EESFF7667B73F92AC
B1546F858456D9
Bokaoi Proxy DAT
EczosaABDwzzaaacsczaDAAzF3DA77315A2A136A25091794
7CD21BACDCE406
Bokaoi Proxy DAT
As expected, very unusable data.
Some pre-processing is required. I only tried a few things like: * removing boundaries * rescale if necessary * convert to grayscale
This only improved the detection only a little. The trick was to define the grammar that the engine is looking for. In the case of extracting hashes, we can do this by:
-c tessedit_char_whitelist=0123456789abcdefABCDEF
Quick tests showed vastly improved results with this simple extra step. While the ideal way ofcourse is to build a corpus of training data, and start from there.
Updated results:
87d37b0073d4d045d29e9c95806c7d018367769714866b901 c7a46e 8011801 Cca1a1aef
a7d5f55
20331 edaadd41 05ce5302621 b9ebe6808aecb787dd73da0b63882c7 8011801 Cca1a10ef
09b63ce48
7e05d6bf0a28233aa0d0abfa220e18834a147f341820d615951809f46f 8011801 Cca1a10ef
5671 b7
961f7bada0037c16e5ae7547d9b14b08988942af8d4a155ad28e224e 8011801 C001aEaef
ce4fa98e
0992229419759be2ecaddcfd2dcce26ce3cdd03823a404875564316b 8011801 Cca1a1aef
459b05eb
88E41CC6BD4EC57BCA8F67F15566475E1EE3FF7667B73F92AC 8011801 8101131 0A1
81946F8564E6D9
EC205BABDC442288803C29DAA2F3D477315A2A136A2BD91794 8011801 1310119 0A1
7CD2184000E406
(Notice the text from columns 2 and 3, which are wrongly detected because of restricted grammar)
For the next test, I tried to capture screenshots of individual hashes into different files:
testdata/hash4.jpg
Identified a sha256 hash: 961f7bada0c37c16e5ae7547d9b14b08988942af8d4a155ad28e224ece4fa98e
testdata/hash2.jpg
Identified a sha256 hash: 2c331edaadd4105ce5302621b9ebe6808aecb787dd73da0b63882c709b63ce48
testdata/hash5.jpg
Identified a sha256 hash: 0992229419759be2ecaddcfd2d00626063cddca823a464875564316b459b05eb
testdata/hash6.jpg
Identified a sha256 hash: 88E41CC6BD4EC57BCABF67F15566475E1EE3FF7667B73F92AC81946F8564E6D9
testdata/hash1.jpg
length=62 87d37b0073d4d045d29e9c95806c7dcf83677697148e6b901c7a46ea7d5f55
testdata/hash3.jpg
Identified a sha256 hash: 7e05d6bf0a28233aa0d0abfa220ef8834a147f341820d6159518c9f46f5671b7
testdata/hash7.jpg
Identified a sha256 hash: EC205BABDC4422888C3C29DAA2F3D477315A2A136A2BD917947CD2184CDCE406
Doing this got me 5 of 7 hashes. I will keep this page updated.